Echelon I/O Model Reference for Smart Transceivers and Neuron Chips User Manual
Page 24
14
Introduction
end-of-loop
processing
begins
TIME
IO_0
1
st
when
clause
(Not to scale)
IO_out call
IO_out call
IO_out call
t
ww
t
ww
t
sol
1
st
when
clause
2
nd
when
clause
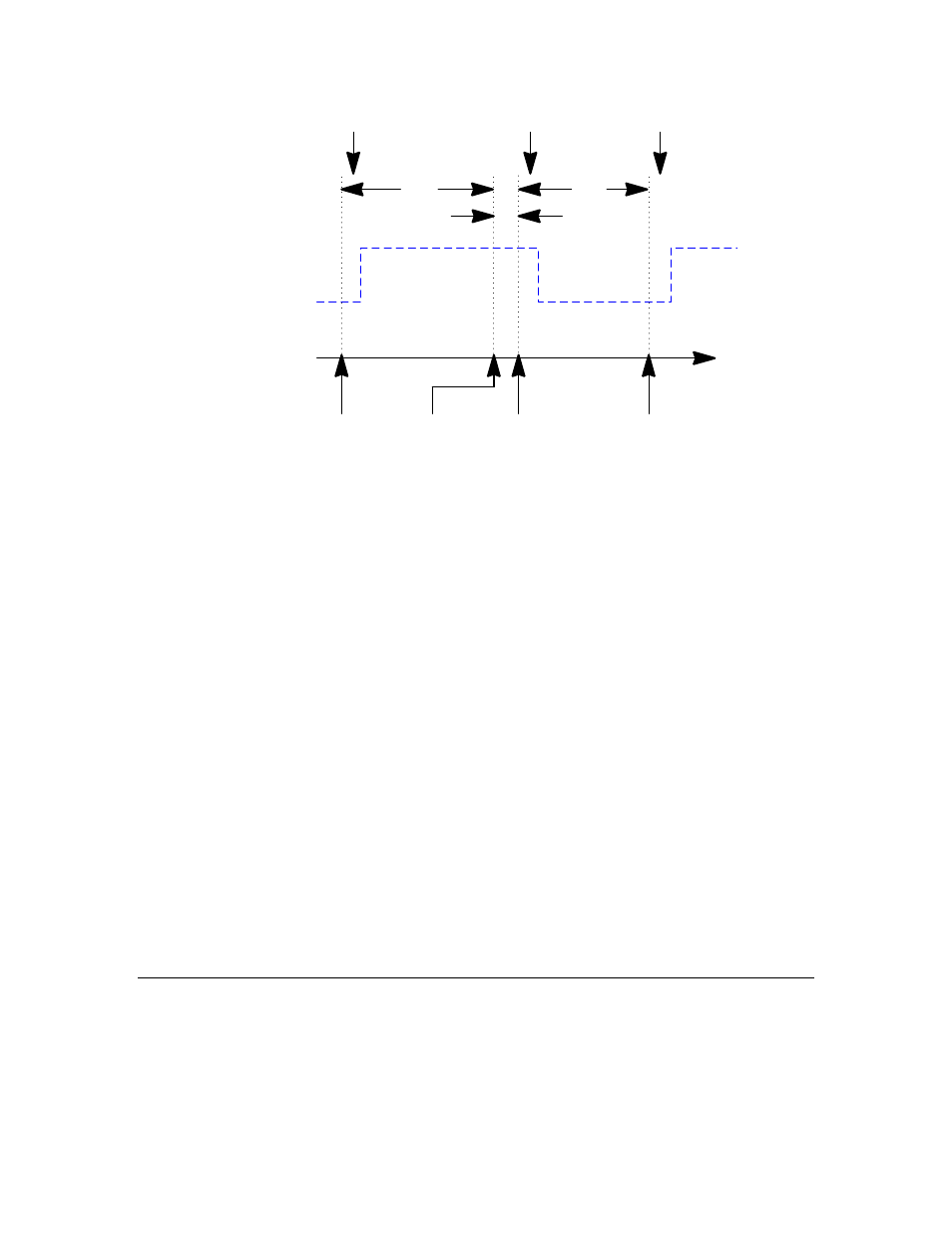
Figure 5. Scheduler Overhead Latency: when Clause to when Clause
The when-clause to when
-
clause latency, t
ww
, in this case includes the execution
time of one io_out() function (which for a Series 3100 device with a 10 MHz input
clock, has approximately 65 μs latency; for a Series 5000 device with an 80 MHz
system clock, this latency is approximately 4 μs) and applies to an event that
always evaluates to TRUE. The actual t
ww
for a particular application depends
on the actual task within the when statement as well as the when event that is
evaluated.
The above example not only measures the best-case minimum latency between
consecutive when clauses (whose events evaluate to TRUE), but also reveals the
scheduler’s end-of-loop overhead latency, t
sol
. As shown in Figure 5, t
ww
is the off-
time period of the output waveform, and t
sol
is the on-time of the output
waveform, minus t
ww
. The scheduler overhead latency, or the scheduler end-of-
loop latency, occurs just before the execution of the last when
clause in the
program.
The latency associated with the return from the io_out() function is small,
relative to that of the execution of the function call itself.
Note: Some I/O models suspend application processing until the task is complete
because they are firmware-driven. These I/O models include: bitshift,
Neurowire, parallel, software serial I/O models, I
2
C, magcard, magtrack, Touch
I/O, and Wiegand. However, they do not suspend network communication (which
is handled by the network processor and the media access processor).
Firmware and Hardware-Related I/O Timing
Information
All I/O updates in a Neuron Chip or Smart Transceiver are performed by the
Neuron firmware using system image function calls.