What content is not crawled – Google Search Appliance Getting the Most from Your Google Search Appliance User Manual
Page 17
Google Search Appliance: Getting the Most from Your Google Search Appliance
Crawling and Indexing
17
•
Product documentation
•
Marketing literature
The Google Search Appliance supports crawling of many types of formats, including word processing,
spreadsheet, presentation, and others.
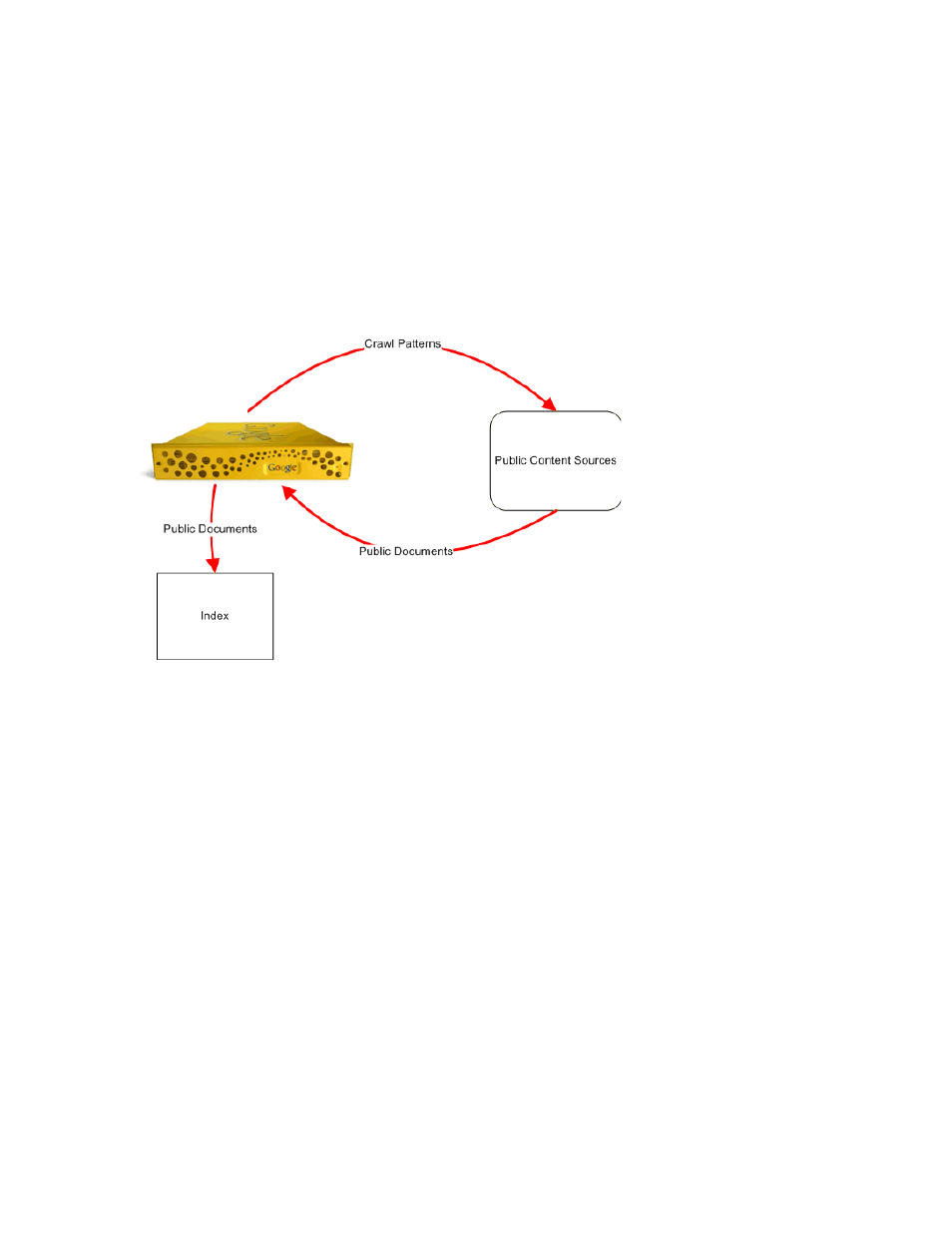
The Google Search Appliance crawls content on web sites or file systems according to crawl patterns
that you specify by using the Admin Console. As the search appliance crawls public content sources, it
indexes documents that it finds. To find more documents, the crawler follows links within the
documents that it indexes. The search appliance does not crawl content that you exclude from the
index.
The following figure provides an overview of crawling public content.
What Content Is Not Crawled?
The Google Search Appliance does not crawl unlinked URLs or links that are embedded within an area
tag. Also, the search appliance does not crawl or index content that is excluded by these mechanisms:
•
Do not follow and crawl URLs that you specify by using the Content Sources > Web Crawl > Start
and Block URLs page in the Admin Console
•
robots.txt file—The Google Search Appliance always obeys the rules in robots.txt (see “Content
Prohibited by a robots.txt File” in Administering Crawl) and it is not possible to override this feature.
Before the search appliance crawls any content servers in your environment, check with the content
server administrator or webmaster to ensure that robots.txt allows the search appliance user agent
access to the appropriate content (see “Identifying the User Agent” in Administering Crawl)
•
nofollow robots META tags that appear in content sources
Typically, webmasters, content owners, and search appliance administrators create robots.txt files and
add META tags to documents before a search appliance starts crawling.