Dell Intel PRO Family of Adapters User Manual
Page 49
Using performance tuning options, the association of the FCoE queues for the second port can be directed to a dif-
ferent non-competing set of CPU cores. The following settings would direct SW to use CPUs on the other processor
socket:
l
FCoE NUMA Node Count = 1: Assign queues to cores from a single NUMA node (or processor socket).
l
FCoE Starting NUMA Node = 1: Use CPU cores from the second NUMA node (or processor socket) in the sys-
tem.
l
FCoE Starting Core Offset = 0: SW will start at the first CPU core of the NUMA node (or processor socket).
The following settings would direct SW to use a different set of CPUs on the same processor socket. This assumes a
processor that supports 16 non-hyperthreading cores.
l
FCoE NUMA Node Count = 1
l
FCoE Starting NUMA Node = 0
l
FCoE Starting Core Offset = 8
Example 2: Using one or more ports with queues allocated across multiple NUMA nodes. In this case, for each NIC
port the FCoE NUMA Node Count is set to that number of NUMA nodes. By default the queues will be allocated evenly
from each NUMA node:
l
FCoE NUMA Node Count = 2
l
FCoE Starting NUMA Node = 0
l
FCoE Starting Core Offset = 0
Example 3: The display shows FCoE Port NUMA Node setting is 2 for a given adapter port. This is a read-only indic-
ation from SW that the optimal nearest NUMA node to the PCI device is the third logical NUMA node in the system. By
default SW has allocated that port's queues to NUMA node 0. The following settings would direct SW to use CPUs on
the optimal processor socket:
l
FCoE NUMA Node Count = 1
l
FCoE Starting NUMA Node = 2
l
FCoE Starting Core Offset = 0
This example highlights the fact that platform architectures can vary in the number of PCI buses and where they are
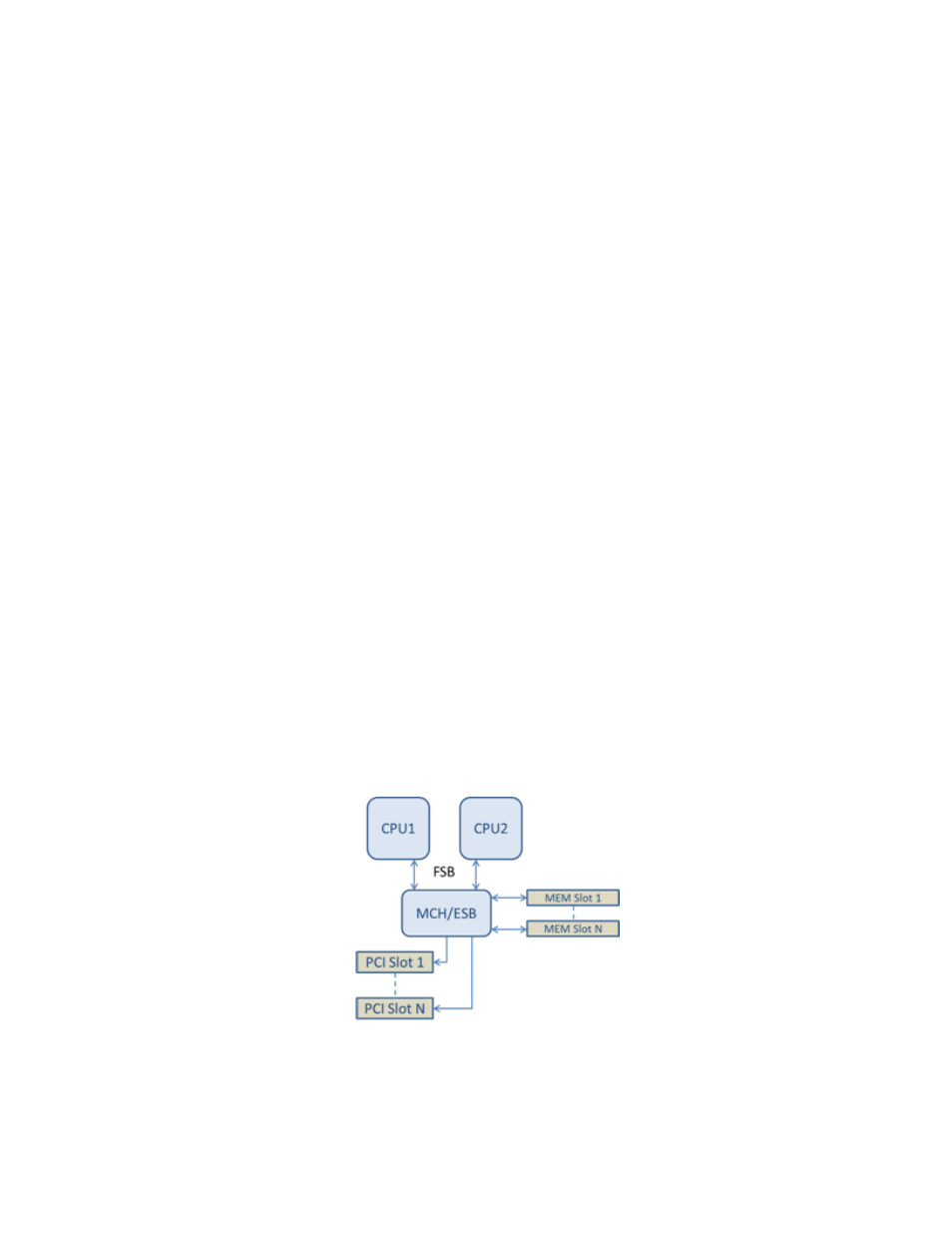
attached. The figures below show two simplified platform architectures. The first is the older common FSB style archi-
tecture in which multiple CPUs share access to a single MCH and/or ESB that provides PCI bus and memory con-
nectivity. The second is a more recent architecture in which multiple CPU processors are interconnected via QPI, and
each processor itself supports integrated MCH and PCI connectivity directly.
There is a perceived advantage in keeping the allocation of port objects, such as queues, as close as possible to the
NUMA node or collection of CPUs where it would most likely be accessed. If the port queues are using CPUs and
memory from one socket when the PCI device is actually hanging off of another socket, the result may be undesirable
QPI processor-to-processor bus bandwidth being consumed. It is important to understand the platform architecture
when using these performance options.
Shared Single Root PCI/Memory Architecture