Book 0 book 1 – IBM 990 User Manual
Page 233
Chapter 8. Capacity upgrades
221
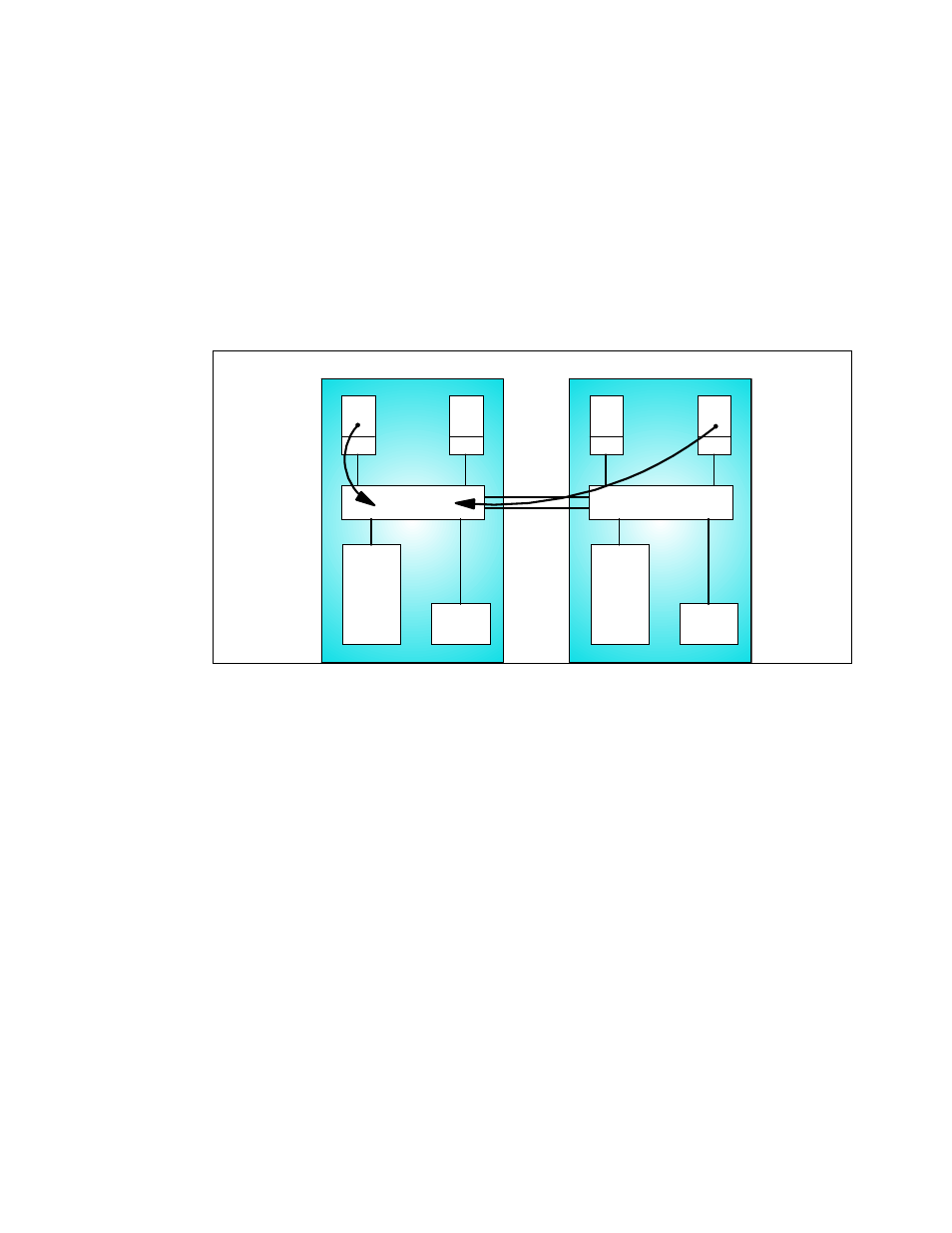
Each book has its own MCM (which contains PUs and an L2 cache), memory cards, and
MBAs with their STIs. Up to four books are connected through L2 caches by concentric rings,
resulting in a single integrated system.
Previous zSeries servers have PU clusters, or PU sets, which are also connected to each
other through L2 caches. But in those cases, all PUs and L2 caches reside in a single MCM.
The z990 multi-MCM design introduces two types of PU to L2 cache access: a “local” access,
when the PU and L2 cache are located in the same MCM (or book), and a “remote” access,
when PU and L2 cache are located in different books.
Figure 8-16 shows a two-book z990 server logical view.
Figure 8-16 Two-book system logical view
In this example, a local access is done by the first PU on Book 0 to its local L2 cache, and a
remote access is done by the last PU on Book 1 to the L2 cache on Book 1. As the access
time of the remote connection is higher than a local one, the performance of such a system
would not be as consistent as a single MCM system, being dependent on the remote access
rates. To avoid this effect, z990 has implemented some optimizations.
The L2 cache is implemented as a processor cache, not as a memory cache. This means that
data (and instructions) are normally residents in the L2 cache on the book where it is being
used by a PU, and not in the book where the associated memory address resides. So in the
previous example, the L2 cache in Book 1 will have the data/instructions used by its local PU
after the remote L2 cache access.
Along with the PU allocation and assignment algorithm during IML, described in “Processor
Unit characterization” on page 52, the PR/SM has a major role in the z990 system
optimization.
The z990 PR/SM has changed to support the multi-book structure and to provide optimal
system performance. PR/SM is aware of the physical book structure, while the logical
partitions do not require awareness about this design. The PR/SM hypervisor manages and
optimizes allocation and dispatching for the underlying physical topology, providing a
transparent multi-book implementation to operating systems. The PR/SM main objective is to
allocate all processors and storage for a logical partition to the same book, and to redispatch
a logical processor back to the same physical processor.
...
L2 Cache
L1
L1
PU
PU
Memory
MBA
...
L2 Cache
L1
L1
PU
PU
Memory
MBA
Book 0
Book 1
Ring
Structure