Figure 1-1, Typical simd operations -3, Simd computations (see figure 1-1) – Intel ARCHITECTURE IA-32 User Manual
Page 31
IA-32 Intel® Architecture Processor Family Overview
1-3
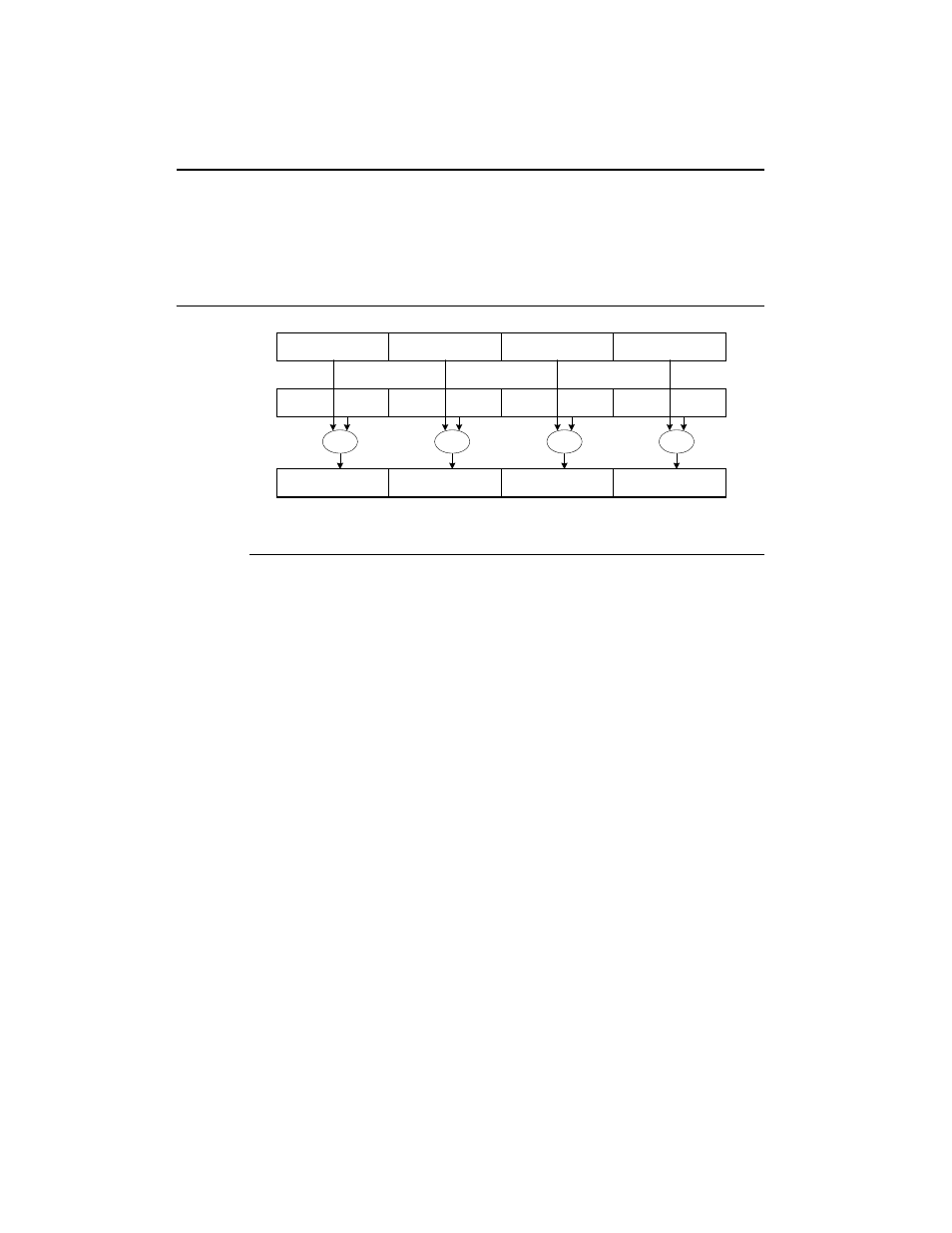
each corresponding pair of data elements (X1 and Y1, X2 and Y2, X3
and Y3, and X4 and Y4). The results of the four parallel computations
are sorted as a set of four packed data elements.
The Pentium 4 processor further extended the SIMD computation model
with the introduction of Streaming SIMD Extensions 2 (SSE2) and
Streaming SIMD Extensions 3 (SSE3)
SSE2 works with operands in either memory or in the XMM registers.
The technology extends SIMD computations to process packed
double-precision floating-point data elements and 128-bit packed
integers. There are 144 instructions in SSE2 that operate on two packed
double-precision floating-point data elements or on 16 packed byte, 8
packed word, 4 doubleword, and 2 quadword integers.
SSE3 enhances x87, SSE and SSE2 by providing 13 instructions that
can accelerate application performance in specific areas. These include
video processing, complex arithmetics, and thread synchronization.
SSE3 complements SSE and SSE2 with instructions that process SIMD
data asymmetrically, facilitate horizontal computation, and help avoid
loading cache line splits.
Figure 1-1
Typical SIMD Operations
X4
X3
X2
X1
Y4
Y3
Y2
Y1
X4 op Y4
X3 op Y3
X2 op Y2
X1 op Y1
OP
OP
OP
OP
O M 15148