Failover and failback capabilities – Dell AX4-5 User Manual
Page 52
52
Understanding Your Failover Cluster
Failover Ring
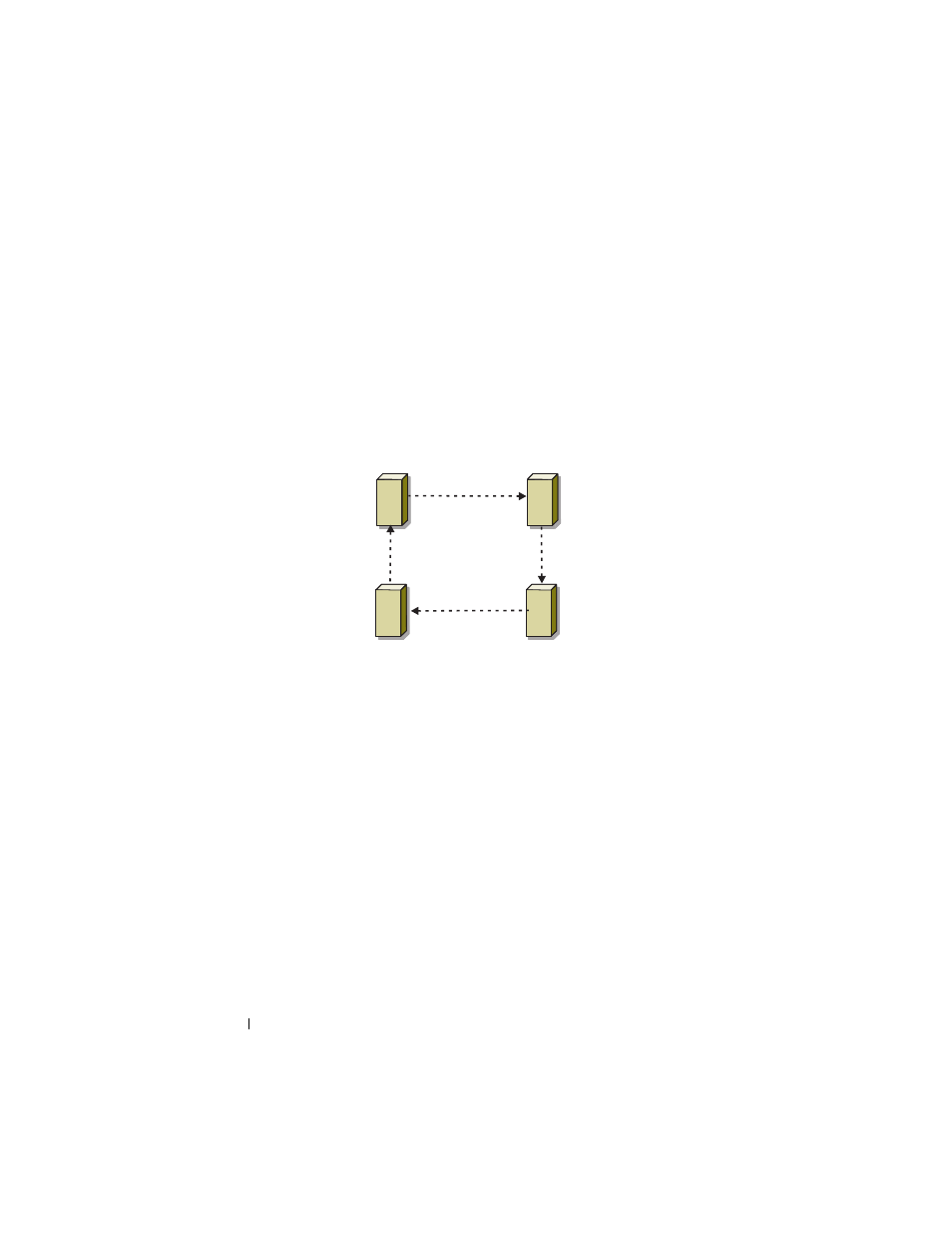
Failover ring is an active/active policy where all running applications migrate
from the failed node to the next preassigned node in the Preferred Owners
List. If the failing node is the last node in the list, the failed node’s
applications failover to the first node.
While this type of failover provides high availability, ensure that the next
node for failover has sufficient resources to handle the additional workload.
Figure 4-4 shows an example of a failover ring configuration.
Figure 4-4.
Example of a Four-Node Failover Ring Configuration
Failover and Failback Capabilities
Failover
When an application or cluster resource fails, WSFC detects the failure and
attempts to restart the resource. If the restart fails, WSFC takes the
application offline, moves the application and its resources to another node,
and restarts the application on the other node.
See "Setting Resource Properties" on page 41 for more information.
Cluster resources are placed in a group so that WSFC can move the resources
as a combined unit, ensuring that the failover and/or failback procedures
transfer all resources.
After failover, Cluster Administrator resets the following recovery policies:
•
Application dependencies
•
Application restart on the same node
•
Workload rebalancing (or failback) when a failed node is repaired and
brought back online
application A
application C
application B
application D