Examples, Figure 2 : fir optimization example, An253 – Cirrus Logic AN253 User Manual
Page 8
AN253
8
4. Examples
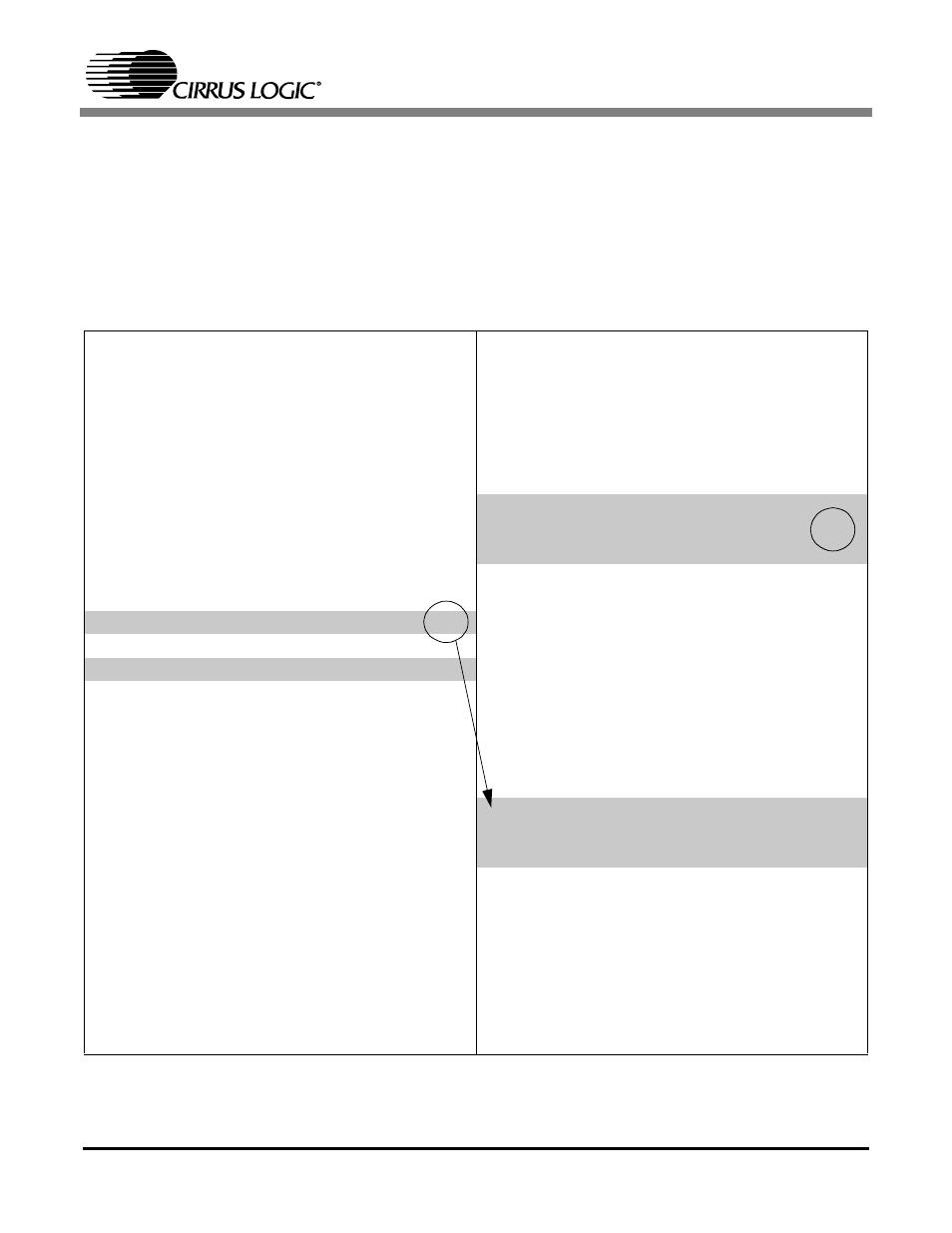
This example illustrates the process of optimizing code for the MaverickCrunch coprocessor at the archi-
tecture level. The following source code is part of a simple real-time implementation of an FIR filter (Figure
2). There is a data dependency in the accumulate portion of the basic source code (on the left). This data
dependency stalls the MaverickCrunch CDP pipeline for 11 cycles. To reduce this penalty, it is possible
to re-arrange the source code to use the ARM cycles in the shadow of the stall.
Figure 2: FIR Optimization Example
To accomplish this optimization (see Figure 2): 1.) Move the index initialization/update code behind the
cfmuld operation; 2.) Add index initialization code just above the loop construct. This optimization results
// Unoptimized FIR
// Optimized FIR
acc = 0;
acc = 0;
add r0,pc,#0x80 ; #0x8544
add r0,pc,#0x80 ; #0x8544
cfldrd c4, [r0]
cfldrd c4, [r0]
for (i = 0; i < n; i++){
// ** initialize array ptrs here **
mov r4,#0
mov r1, r5
b 0x8508 ; (fir + 0x6c)
mov r0, r7
acc += h[i] * z[i];
for (i = 0; i < n; i++){
add r1,r5,r4,lsl #3 // Ptr
mov r4,#0
cfldrd c0, [r1]
b 0x8508 ; (fir + 0x6c)
add r0,r7,r4,lsl #3 // Ptr
cfldrd c1, [r0]
acc += h[i] * z[i];
cfmuld c0, c0, c1 // <-- 11-cycles
cfldrd c0, [r1]
cfaddd c4, c4, c0 // <-- stalled
cfldrd c1, [r0]
cfmuld c0, c0, c1
add r4,r4,#1
cmp r4,r6
// ** increment ptrs here **
blt 0x84d8 ; (fir + 0x3c)
add r1,r5,r4,lsl #3
add r0,r7,r4,lsl #3
}
cfaddd c4, c4, c0
add r4,r4,#1
cmp r4,r6
blt 0x84d8 ; (fir + 0x3c)
}
1
2