0 seaclass process, 1 prepare data, 1 bottom samples – Triton Sediment User Manual
Page 8: 2 load/create imagery
Page 5
2.0 SeaClass Process
2.1 Prepare Data
2.1.1 Bottom Samples
One requirement for the classification process using SeaClass is
having bottom information to use for the training set. This
information can come from diver observations, video transects, or
classical sediment sampling programs.
Before beginning the classification process, it is very useful to load
the sample information into Perspective as
Feature
files. Format the
sample data in CSV files using Microsoft Excel or a text editor using
the required data format for Features outlined in:
available from our downloads webpage. Make one Feature CSV file
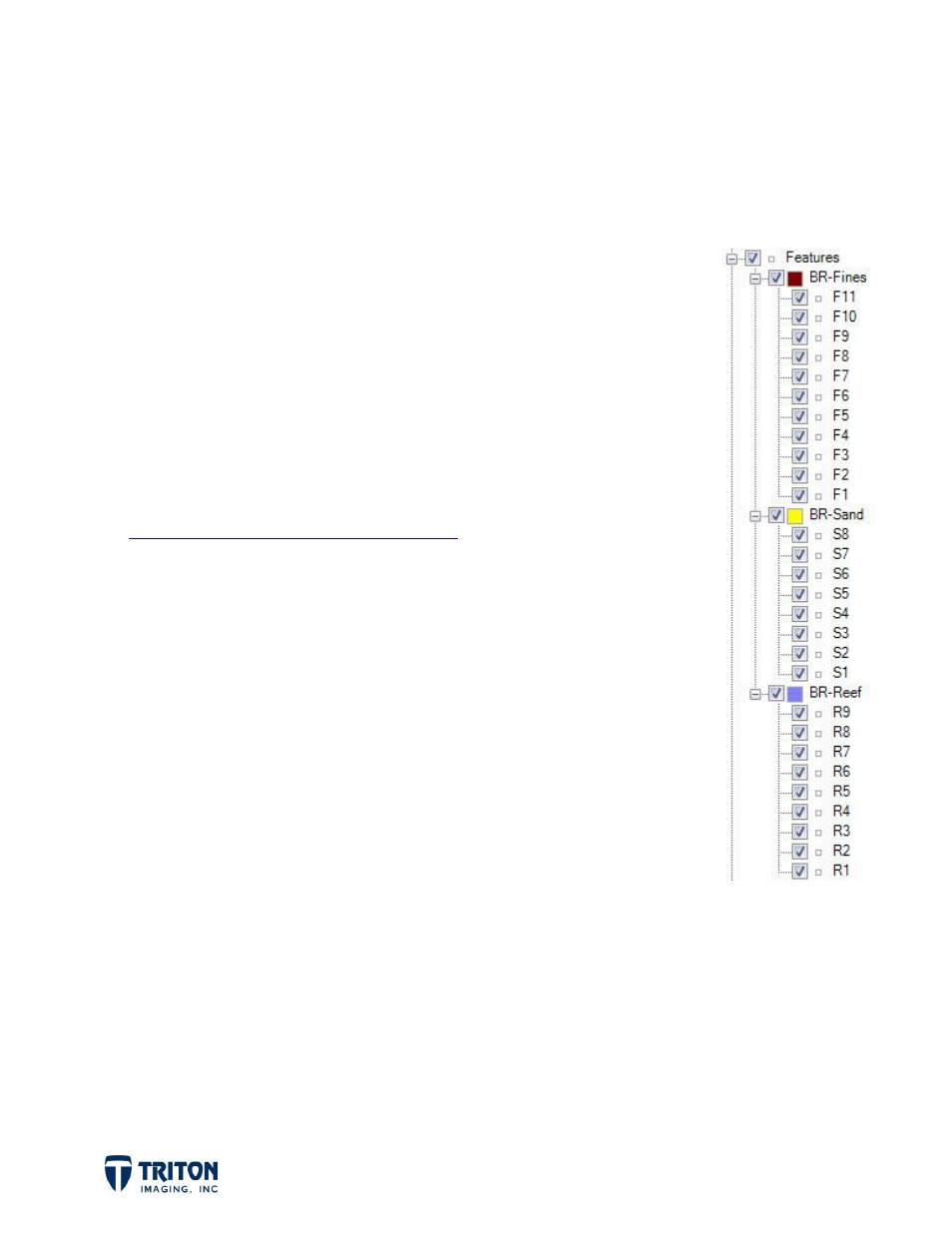
for each bottom type and load into unique File Tree groups. In the
example shown to the right, there are three
Feature
groups: Fines,
Sand, and Reef (BR stands for Barrett Reef), with several samples
loaded into each group from the CSV files containing the sample
information.
2.1.2 Load/Create Imagery
The other requirement for the classification process using SeaClass
is having an image to classify. This can be either a GeoTiff file or a
sidescan mosaic created in Perspective or with Isis/TritonMap.
Note that this imagery data does not have to be in the project during the first two steps
of the classification process. Creating the training set and the neural net are independent
from the imagery and can be added to the project at any time for classification.
If there is no bottom sample information, the user can pick points for the training set
directly from the imagery to be classified. In this case it is essential that the imagery is
either created in Perspective or loaded into Perspective before creating a Training Set so
the imagery can be used as part of the process.