Intel IRP-TR-03-10 User Manual
Page 5
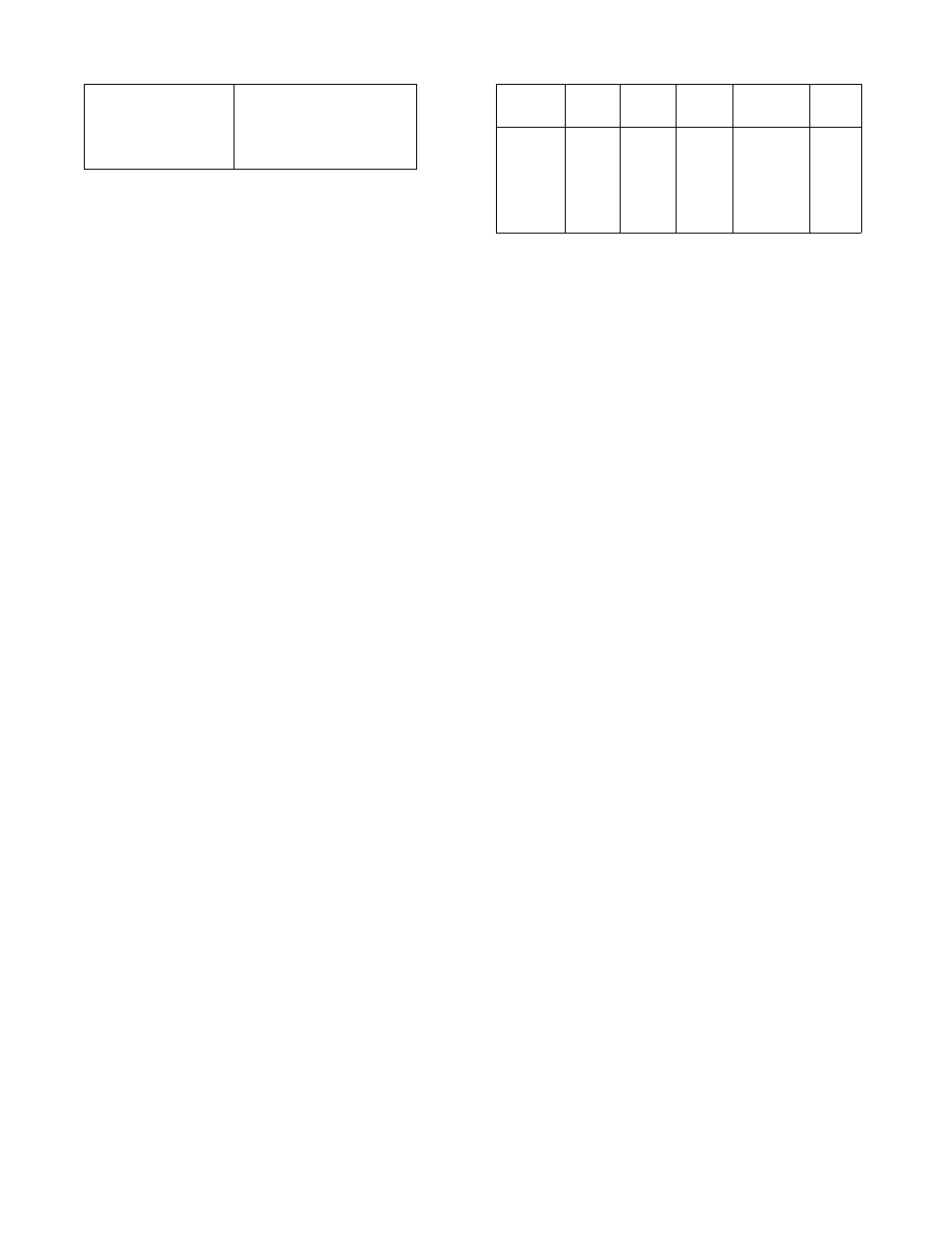
cfs lka --clear
exclude all indexes
cfs lka +db1
include index db1
cfs lka -db1
exclude index db1
cfs lka --list
print lookaside statistics
Figure 1. Lookaside Commands on Client
at a specified pathname. It computes the SHA-1 hash
of each file and enters the filename-hash pair into
the index file, which is similar to a Berkeley DB
database [13]. The tool is flexible regarding the lo-
cation of the tree being indexed: it can be local, on a
mounted storage device, or even on a nearby NFS or
Samba server. For a removable device such as a USB
storage keychain or a DVD, the index is typically lo-
cated right on the device. This yields a self-describing
storage device that can be used anywhere. Note that an
index captures the values in a tree at one point in time.
No attempt is made to track updates made to the tree
after the index is created. The tool must be re-run to
reflect those updates. Thus, a lookaside index is best
viewed as a collection of hints [21].
Dynamic inclusion or exclusion of lookaside de-
vices is done through user-level commands. Figure 1
lists the relevant commands on a client. Note that mul-
tiple lookaside devices can be in use at the same time.
The devices are searched in order of inclusion.
5 Evaluation
How much of a performance win can lookaside
caching provide? The answer clearly depends on the
workload, on network quality, and on the overlap be-
tween data on the lookaside device and data accessed
from the distributed file system. To obtain a quan-
titative understanding of this relationship, we have
conducted controlled experiments using three different
benchmarks: a kernel compile benchmark, a virtual
machine migration benchmark, and single-user trace
replay benchmark. The rest of this section presents our
benchmarks, experimental setups, and results.
5.1 Kernel Compile
5.1.1 Benchmark Description
Our first benchmark models a nomadic software de-
veloper who does work at different locations such as
his home, his office, and a satellite office. Network
connection quality to his file server may vary across
these locations. The developer carries a version of his
Kernel
Size
Files Bytes
Release Days
Version (MB) Same Same
Date Stale
2.4.18
118.0 100% 100% 02/25/02
0
2.4.17
116.2
90%
79% 12/21/01
66
2.4.13
112.6
74%
52% 10/23/01
125
2.4.9
108.0
53%
30% 08/16/01
193
2.4.0
95.3
28%
13% 01/04/01
417
This table shows key characteristics of the Linux kernel ver-
sions used in our compilation benchmark. In our experiments,
the kernel being compiled was always version 2.4.18. The
kernel on the lookaside device varied across the versions
listed above. The second column gives the size of the source
tree of a version. The third column shows what fraction of the
files in that version remain the same in version 2.4.18. The
number of bytes in those files, relative to total release size, is
given in the fourth column. The last column gives the differ-
ence between the release date of a version and the release
date of version 2.4.18.
Figure 2. Linux Kernel Source Trees
source code on a lookaside device. This version may
have some stale files because of server updates by other
members of the development team.
We use version 2.4 of the Linux kernel as the source
tree in our benchmark. Figure 2 shows the measured
degree of commonality across five different minor ver-
sions of the 2.4 kernel, obtained from the FTP site
ftp.kernel.org.
This data shows that there is a
substantial degree of commonality even across releases
that are many weeks apart. Our experiments only use
five versions of Linux, but Figure 3 confirms that com-
monality across minor versions exists for all of Linux
2.4. Although we do not show the corresponding fig-
ure, we have also confirmed the existence of substantial
commonality across Linux 2.2 versions.
5.1.2 Experimental Setup
Figure 4 shows the experimental setup we used
for our evaluation. The client was a 3.0 GHz Pen-
tium 4 (with Hyper-Threading) with 2 GB of SDRAM.
The file server was a 2.0 GHz Pentium 4 (without
Hyper-Threading) with 1 GB of SDRAM. Both the
machines ran Red Hat 9.0 Linux and Coda 6.0.2, and
were connected by 100 Mb/s Ethernet. The client file
cache size was large enough to prevent eviction during
the experiments, and the client was operated in write-
disconnected mode. We ensured that the client file
cache was always cold at the start of an experiment.
To discount the effect of a cold I/O buffer cache on the
server, a warming run was done prior to each set of ex-
periments.
4